marco cognetta theoretically good with computers
blunder.clinic - dont blunder
Discuss on other sites: HackerNews, Lichess
Today, I launched blunder.clinic, a daily chess puzzle app that provides realistic positions for you to try to not blunder on. These are similar to traditional chess puzzles (i.e., tactics), but different in a few key ways.
There are two popular ways to self-study chess: tactics and following along with professional games or with an engine. These are obviously helpful, but both have downsides.
When playing puzzles, just by knowing you are playing a puzzle means that you are biased towards looking for specific types of moves (checkmates, queen sacrifices, etc.). But in real life, you don't know what positions actually have tactics available, so you can waste your time looking for tactics, or, even worse, make a blunder by thinking there is a tactic when there really isn't.
When following along with an engine, there are tons of positions where an engine comes up with a move that you simply would never have seen and can't possibly understand. These are very low signal for learners, and it is hard to differentiate between positions like that and high-signal positions that are on the edge of your ability.[1]
blunder.clinic addresses both of these problems by giving you positions where people of your skill level actually blundered, but the best move is something that isn't too far beyond your capability to understand and learn from.
Overall, the main purpose of blunder.clinic is to help you stop blundering easy positions!
blunder.clinic vs Chess Puzzles
Chess puzzles are positions where the other side has made a mistake and you have to execute a series of moves that capitalize on it. These come in various styles like checkmating patterns, forks, pins, etc., and they are pretty helpful for improving at chess.
blunder.clinic, on the other hand, is just positions where you shouldn't blunder. There doesn't need to be a tactic (though sometimes there is), the other side might not have blundered, or the game may be completely even. All that matters is that, when this position was reached in real life, the player made a mistake, but the best move (one that wasn't a blunder) is not very hard to find.
blunder.clinic Interface
Every day, for a given rating, blunder.clinic provides 6 puzzles: two easy, two medium, and two hard. When you start the puzzles, you will see a board position and your only job is to not blunder. When you pick a move, we will let you know if you got it right (if it wasn't a blunder) or give you the chance to try again or to just see the solution.
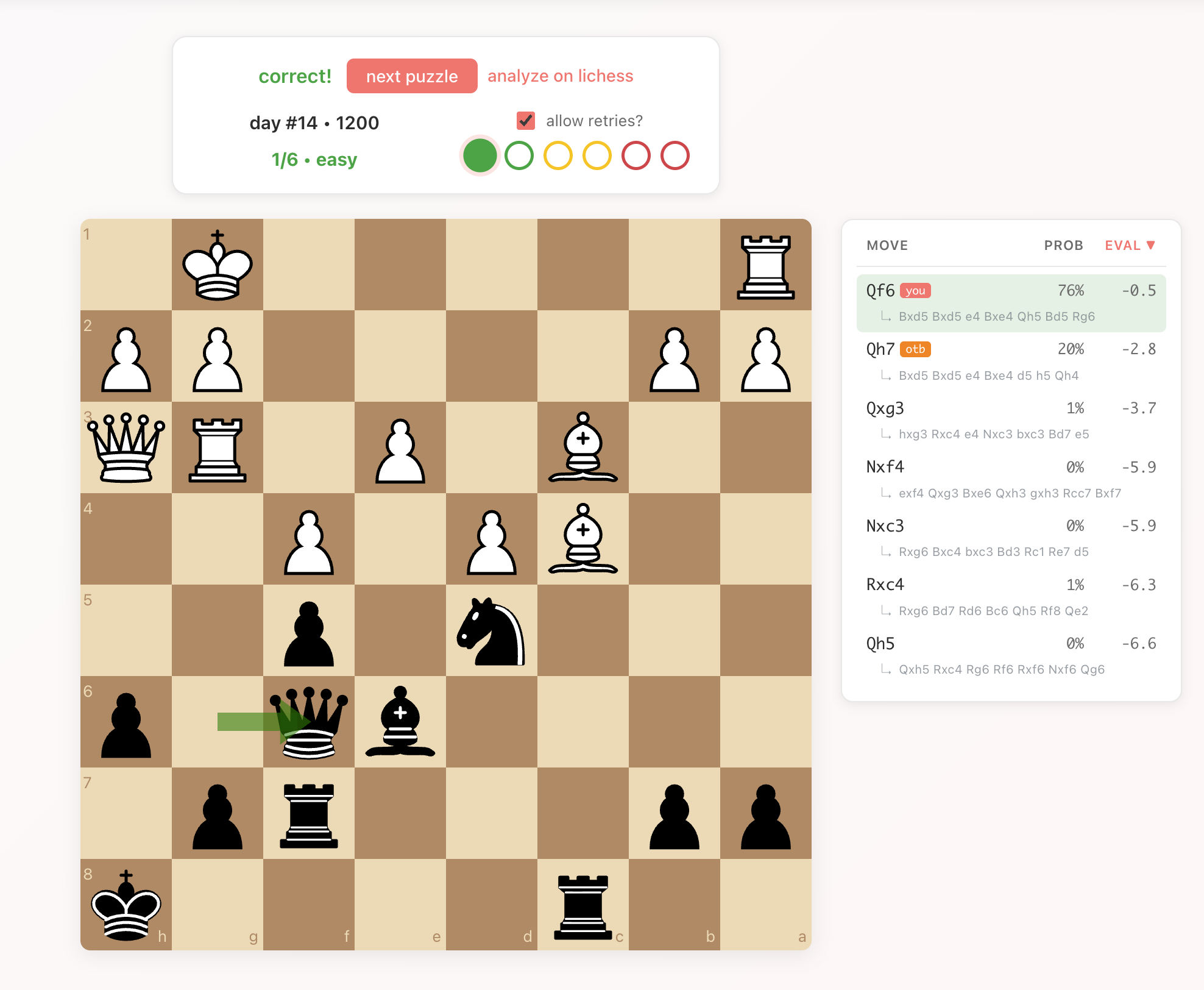
Once you reveal the solution, you can see the best move(s) plus some other high-probability moves and all of their evaluations and probabilities. You can also see the best continuation from each position by clicking on the algebraic notation below each move. This will animate the next couple of moves, and is really helpful for figuring out why a particular move is a blunder (usually something that happens a few moves later).
Since all of the positions are from real Lichess games, we provide a marker for the move that was actually made in the real game (the orange otb button, for "over-the-board") as well as an analyze on lichess button to jump directly to the game's analysis in Lichess, preloaded to the exact position so that you can explore the position in more depth.
At the end, you will receive a score along with a copy-pasteable blurb to share with your friends!
https://blunder.clinic/ #1 • 1500
🟩🟩🟨🟨🟥🟥
6/6 ⭐💪
https://blunder.clinic/ #1 • 1800
🟩🟩🟨⬜⬜🟥
4/6The colored vs gray blocks tell you if you got the easy/medium/hard ones correct, the ⭐ signifies you got a perfect score, and the 💪 is for "hard mode".
Hard Mode
blunder.clinic tries to not provide any signal that could bias your decisions. Just like how knowing you are playing a tactics puzzle means you look for certain types of moves, knowing you are solving an "easy" puzzle biases your thinking. Therefore, we provide a hard mode toggle on the starting screen that randomizes the order of the puzzles and hides their difficulty. This is a much more realistic setting, since in real games you have no idea how hard a given position really is.
Curating the Puzzle Dataset
We used the Maia chess model family, the Stockfish chess engine, and the Lichess game database to curate the puzzles.
We quantify the difficulty of finding a position by using the Maia chess models. Unlike traditional chess engines that are designed to be as good as possible, Maia is designed to be as human-like as possible. Maia takes a board and a player rating as input and outputs a probability distribution over all possible moves that signifies how likely it is that a player of the given skill level would have made that move. We can use this output to answer "Do we think it is likely that a player of your rating would have picked the best move?".
These models aren't perfect, but they are much more accurate at predicting human behavior than anything else out there. We used the Maia2 models, but are looking forward to transitioning to the Maia3 models once they are available.
The puzzle curation has two steps. We first crawled thousands of games from the Lichess game dataset. These games were filtered until we had several thousand games for each of our desired ratings (1200, 1500, 1800 rapid for now).[2] We then searched each game for positions where one player made a blunder according to Stockfish,[3] but according to Maia, the best move had above a certain probability threshold, meaning it was sufficiently easy to find.
Once this list was curated, we filtered it further to make sure that the positions were meaningful and fun. For example, we made sure to find all the other moves that were "close enough" to the best move, so that we don't count your choice as wrong when it is nearly as good as the best choice.[4] We also made sure that the positions aren't too easy (like if they have just two possible moves, and one is obviously wrong). And, we checked that the move that was actually played over-the-board was something reasonable and not just a misclick or obvious blunder due to time pressure.[5] A few other heuristics were applied to get a good base set of puzzles, which were then sorted into easy, medium, and hard depending on the probability of the best move (easy being roughly >75%, medium being ~55-70%, and hard being 40-50%).
Limitations
The Maia models are quite good, but they aren't perfect. They provide a good estimate of the probability of players of a specific rating choosing a specific move in aggregate, but everyone has different strengths and weaknesses. And, in playtesting, we consistently found that our thresholds for easy, medium, and hard were too difficult and we had to shift things significantly. For example, our original setup was "hard" being that the probability of a player picking the best move was below 25%, and it was so difficult that players rated above 2000 were not consistently getting perfect scores on the 1200-rated puzzles. You may find positions that seem way too easy or way too hard for their label, but please understand that no system built on probabilistic models like this is perfect.
We also only provide puzzles for 1200-, 1500-, and 1800-rated positions for now, for two reasons. First, Maia only covers the 1100-1900 rating range,[6] so we cannot even make accurate estimates outside of this rating range. And second, it takes several hours on my personal computer to process enough games to get a few hundred usable positions per rating. There's a lot of room to optimize the curation pipeline, so I do not expect this to be a blocker for long, but up until now, I have worked more on the curation heuristics than anything else.
| [1] | This is the "Goldilocks Zone" for learning: just hard enough to stretch your ability, but not too hard so as to be discouraging. |
| [2] | We filtered by games that already had evaluations present, but of course we could have performed our own. |
| [3] | Blundering has a specific numerical interpretation. We use the same one that Lichess uses in its analysis board, which is if your expected chance of winning drops by more than ~14%. |
| [4] | For example, if the best move had an evaluation of 1.3, but you pick one that has an evaluation of 1.29, that should count as correct. Compared to picking a move with an evaluation of 0.8, which is a small but noticeable drop, or something like -4.5, which is a massive blunder. Our exact threshold is that the move you pick should not decrease your chances of winning by more than 4%. |
| [5] | We did this by making sure the probability of the played move was >5%. |
| [6] | Maia3 will have a wider range, according to the paper and some notes online. |